Xv6 Labs 概述
Xv6
xv6是MIT 6.1810操作系统课程所使用的一个基于 riscv 的操作系统。使用 C 语言编写,运行在 qemu 上。
本文我希望从我做过的xv6实验中挑选出一些有趣的部分简单说明并 加以总结归纳,既可以用于回顾知识,也用于面试。
以下为基本介绍:
- lab 的基本思想是为基于 riscv 的开源操作系统 xv6 增加新的功能和特性,下面是一些实例。
- 基于内核trap处理机制及其他模块,增加新的
syscall,例如:pgaccess通过访问PTE权限位查看哪些page被访问、alarm注册一个函数在特定时钟周期次数后调用等。 - 根据内核分配页面的机制和设置PTE的权限,实现对内存页的引用计数进而实现
fork的COW特性。 - 编写与 e1000 网卡交互的驱动代码,根据其手册设置网络包格式进行发送、处理设备中断来接收网络包。
- 对 xv6 数据结构进行拆分,增加锁的数量和细度,以提高并发性能。例如将 FS 的
block cache list更改为Hash table,为每个bucket维护锁,提高了处理cache的速度。 - 重新设计文件
inode,增加二级 block 号,以提高文件最大大小。 - 实现符号链接,并为
open系统调用增加O\_NOFOLLOWflag,设置这个 flag 会阻止符号链接的递归查找。
说说xv6如何处理trap
- 硬件提供了一个特权级寄存器stvec,os负责设置设置其权限并设置它为trap入口的地址
- trap发生的时候,统一跳转到对应的地址由os进行处理
Usertrap
- 用户地址空间包含一个trap page,用来保存
- 用户寄存器
sstatus:表明发生trap前在哪个特权级sepc:trap发生前执行的指令kernel_satp表示内核地址空间的 token ,即内核页表的起始物理地址;kernel_sp表示当前应用在内核地址空间中的内核栈栈顶的虚拟地址;trap_handler表示内核中 trap handler 入口点的虚拟地址。
- 这个 trap page 的虚拟地址是相同的,由内核设置并保存
- 进程初始化时内核设置好
trap_handler,kernel_sp,kernel_satp此后不再更改 - trap发生时,
ecall提升特权级,跳入stvec指向的地方,开始处理 trap page - 首先将
sscratch和sp进行交换,sscratch保存的是 trap page 的地址 - 通过sp 保存寄存器,读取
kernel_satp,kernel_sp,trap_handler,待使用完之后,将sscratch中保存的原来的sp存入trap page的sp中 - 设置sp 为
kernel_sp,设置satp为kernel_satp,然后刷新vma,这里才进入内核内存空间。 - 最后跳转到
tarp_handler
返回
- 首先设置sscratch为trap page地址,转换到用户虚拟地址
- 然后恢复寄存器
- 通过sret返回用户空间,并降低特权级
处理
- scause/stval 分别会被修改成这次 Trap 的原因,以及相关的附加信息。
- trap_handler根据其内容处理trap,以及根据syscall number处理syscall
物理页分配
分配器(allocator)定义在kernel/kalloc.c里。分配器的数据结构是由空闲物理页组成的链表。每个空闲页在列表里都是struct run。因为空闲页里什么都没有,所以空闲页的run数据结构就保存在空闲页自身里。这个空闲列表使用自旋锁进行保护。
pgaccess如何实现的?
pgaccess这个系统调用接收一个虚拟地址和一个num,内核会检查从这个虚拟地址开始num个page是否被访问,然后返回一个bitsmap。
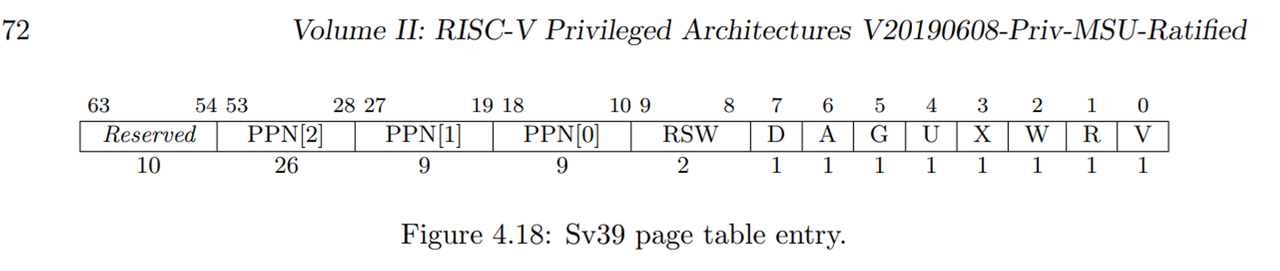
xv6是基于riscv的os,它的虚拟内存机制是riscv的Sv39
对应的页表中的PTE 64bit由10bits的保留bits,44bits的PPN和2bits保留权限bit和8bits权限bits组成
- V(Valid):仅当位 V 为 1 时,页表项才是合法的;
- R(Read)/W(Write)/X(eXecute):分别控制索引到这个页表项的对应虚拟页面是否允许读/写/执行;
- U(User):控制索引到这个页表项的对应虚拟页面是否在 CPU 处于 U 特权级的情况下是否被允许访问;
- G:暂且不理会;
- A(Accessed):处理器记录自从页表项上的这一位被清零之后,页表项的对应虚拟页面是否被访问过;
- D(Dirty):处理器记录自从页表项上的这一位被清零之后,页表项的对应虚拟页面是否被修改过。
内核要做的,就是通过虚拟地址找到对应PTE,然后检查Access bit
页表的riscv支持
satp 寄存器
satp 寄存器负责控制页表基地址和地址转换模式。在 SV39 模式下,satp 寄存器的结构如下:
scss
Copy code
63 60 59 44 43 0
+---------+---------+---------+
| MODE(4) | ASID(16)| PPN(44) |
+---------+---------+---------+
MODE:地址转换模式。对于 SV39,MODE的值为 8。ASID:地址空间标识符(Address Space Identifier),用于区分不同的进程。PPN:页表根基地址的物理页号(Physical Page Number)。
设置 satp 寄存器
在进程切换时,需要更新 satp 寄存器以切换到新进程的页表。以下是设置 satp 寄存器的步骤:
- 保存当前进程的上下文: 在进程切换前,保存当前进程的所有上下文信息,包括通用寄存器、程序计数器(PC)、以及
satp寄存器。 - 更新
satp寄存器: 设置satp寄存器以指向新进程的页表基地址,并更新ASID以标识新进程。 - 恢复新进程的上下文: 恢复新进程的寄存器状态和程序计数器。
如何通过虚拟地址找到这个PTE?
sv39的虚拟地址有效bits有39个,但是这里27个bits用于对应多级页表
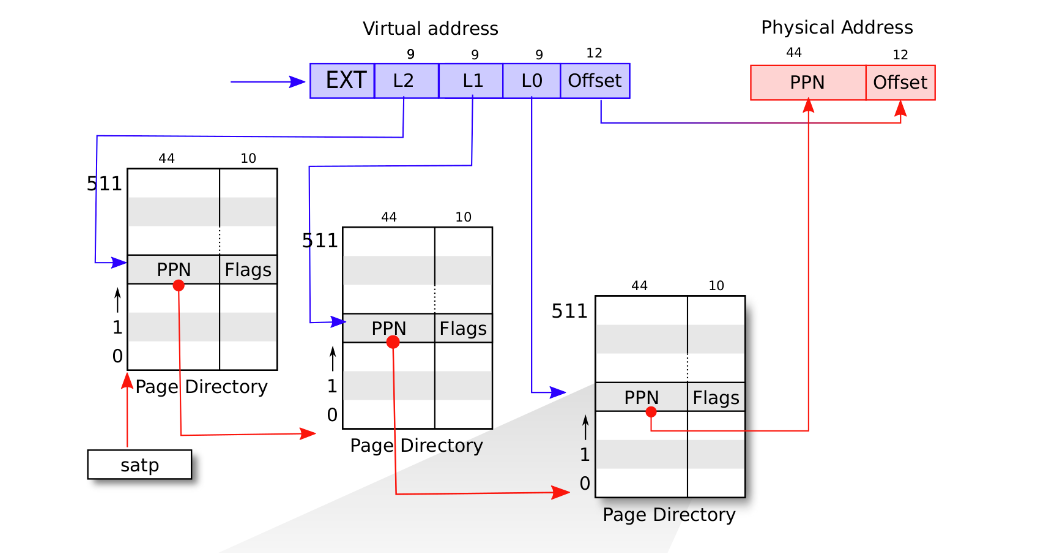
首先内核会维护最高一级页表的物理地址,一个虚拟地址的39位的高9位对应最高层页表的偏移量,
通过最高一级页表的物理地址和偏移量会得到最高一层页表中的PTE,然后查看其44bits的物理地址,找到对应的二级页表的位置,然后查看虚拟地址的第二个9bits查找,然后查找第三级,找到之后,就可以查看PTE的权限位检查是否被access。
为啥每一级页表都是9bits来进行偏移?
9bits对应的是512个PTE,每个PTE的大小是8byte,也就是4096bytes,对应的是4kb,正好是一个内存页的大小。
alarm如何实现的?
完成两个系统调用,第一个sigalarm,调用了这个系统调用之后,用户程序在进行了特定数量的ticks之后,就必须alarm一下,alarm一下就是要调用sigalarm传入参数中的函数指针指向的函数。而另一个sigreturn的作用是从alarm一下所调用的函数中返回原来的指令处继续指向。因为这个函数已经不能自己返回,所以必须借助系统调用返回。
这里时钟周期的含义是,cpu触发一个时钟中断。
所以实现这个需要在时钟中断也就是trap handler处做手脚
- 需要在进程的数据结构中增加成员,用来保存注册函数的地址和等待几次时钟周期和已经等待了几次
- 当触发时钟中断时,增加等待次数,并判断是否相等
- 如果相等,修改用户的sepc,指向注册函数地址
- 由于返回用户空间之后,注册函数可能会修改信息,所以我们还需要在内核中保存寄存器信息,保存callee registers就行
sigreturn系统调用需要
- 将用户的sepc设置成原来的sepc地址
- 从内核proc中读取callee registers,写入trap page
- 返回
有哪些中断类型?
- 软件中断 (Software Interrupt):由软件控制发出的中断
- 时钟中断 (Timer Interrupt):由时钟电路发出的中断
- 外部中断 (External Interrupt):由外设发出的中断
时钟中断是干什么的?如何实现?
主要用于分时抢占式调度,当发出时钟中断时会切换下一个进程运行
有一个计数器用来统计处理器自上电以来经过了多少个内置时钟的时钟周期。在 RISC-V 64 架构上,该计数器保存在一个 64 位的 CSR mtime 中,我们无需担心它的溢出问题,在内核运行全程可以认为它是一直递增的。
另外一个 64 位的 CSR mtimecmp 的作用是:一旦计数器 mtime 的值超过了 mtimecmp,就会触发一次时钟中断。这使得我们可以方便的通过设置 mtimecmp 的值来决定下一次时钟中断何时触发。
每次触发时钟中断时,我们都需要设置mtimecmp来设置下一次中断的时间,这样就保证了时钟中断
中断屏蔽?
sstatus 的 sie 为 S 特权级的中断使能,能够同时控制三种中断,如果将其清零则会将它们全部屏蔽。即使 sstatus.sie 置 1 ,还要看 sie 这个 CSR,它的三个字段 ssie/stie/seie 分别控制 S 特权级的软件中断、时钟中断和外部中断的中断使能。
调度方式?
xv6使用抢占式分时调度
其他的调度方式例如协作式调度、FIFO调度、多级反馈调度等等
进程数据结构要保存哪些信息?
// Saved registers for kernel context switches.
struct context {
uint64 ra;
uint64 sp;
// callee-saved
uint64 s0;
uint64 s1;
uint64 s2;
uint64 s3;
uint64 s4;
uint64 s5;
uint64 s6;
uint64 s7;
uint64 s8;
uint64 s9;
uint64 s10;
uint64 s11;
};
// Per-process state
struct proc {
struct spinlock lock;
// p->lock must be held when using these:
enum procstate state; // Process state
void *chan; // If non-zero, sleeping on chan
int killed; // If non-zero, have been killed
int xstate; // Exit status to be returned to parent's wait
int pid; // Process ID
int trace_mask; // Trace mask
// wait_lock must be held when using this:
struct proc *parent; // Parent process
// these are private to the process, so p->lock need not be held.
uint64 kstack; // Virtual address of kernel stack
uint64 sz; // Size of process memory (bytes)
pagetable_t pagetable; // User page table
struct trapframe *trapframe; // data page for trampoline.S
struct context context; // swtch() here to run process
struct file *ofile[NOFILE]; // Open files
struct inode *cwd; // Current directory
char name[16]; // Process name (debugging)
};
锁,进程状态:运行、就绪、停止,程序对应内核栈地址,程序内存大小,pagetable,trap page地址,进程在内核中切换需要的上下文:sp ra callee rgs,程序名称,程序打开的文件描述符,程序的inode
任务切换
现在有多道程序在内存中,我们当然不能让他们依次执行,那就没有了意义,批处理也能完成
多道程序的目的就是为了在一个程序进行io或者其他不需要cpu的事情的时候,可以放出cpu让其他程序进行运行,所以程序绝对不是依次执行的.
这也就意味着我们会遇到程序切换的情况,这里我们用任务称程序,是更贴切的称呼
我们需要考虑一下任务切换的过程中需要保存哪些信息
- 用户程序切换到内核之后,用户程序使用的寄存器都保存在内核栈上的某个地方,这里我们在写trap的时候就已经接触过了
- switch函数在切换的时候,我们采用的方式是返回跳转,设置好ra的地址之后,调用ret自动跳转到对应位置执行.所以我们需要保存ra的地址在任务空间.此外我们需要设置sp,也就是在内核栈中保存用户信息的地方,用于恢复任务的执行,此外,由于我们的汇编函数没法保存callee寄存器,所以我们需要手动保存,也保存在任务空间
pub struct TaskContext {
/// return address ( e.g. __restore ) of __switch ASM function
ra: usize,
/// kernel stack pointer of app
sp: usize,
/// callee saved registers: s 0..11
s: [usize; 12],
}
如何实现fork的COW
- 我们需要使用PTE中保留的2bits用来新增一个COW权限
- 如果不新增权限,没办法区别本来是R权限的页和由W改成R的页,进而我们没法区别是要进行COW还是程序发生了错误。
- 首先,在创建进程并进行内存copy的时候,不进行copy,而是映射到相同的物理地址
- 对于只有R权限的PTE,不需要多余处理
- 对于有W权限的PTE,我们需要清除父进程的W权限,防止修改,并设置COW权限
- 当用户尝试对页面进行写时,会触发usertrap,page fault 我们需要在trap handler中捕获这个trap,并检查
- 如果没有COW权限,说明程序错误,报错并切换下一个进程
- 如果有COW权限,需要分配新的物理内存,复制内容,设置W权限和清除COW权限,这里还需要找到父进程页表,设置权限
- 然后返回用户空间,重新执行上一条指令
- page引用计数是为了在所有进程退出时,free物理内存
- 需要在page的数据结构中维护新的字段,用来记录引用计数,在发生COW的时候,增加引用计数,在程序退出时减少引用计数,并在引用计数为0时释放物理内存
有哪些程序段不需要COW
rodata段
Text 段,但是也不一定,gdb就会更改text段(xv6未处理)
如何实现的e1000
e1000在内核内存中对应一个ring buffer,里面保存e1000定义的描述符格式,描述符中包含要发送的网络包的地址和长度,内核放入描述符之后,就可以设置DMA管理的e1000的寄存器让它来读取。e1000读取描述符之后,就可以到对应的地址找到要发送的网络包并发送,当网络包被发送,e1000会设置网络包中的bit为1。
我的工作只是写入这个ring buffer,具体流程是,从尾指针开始检查,如果没有被使用,直接使用这个,如果被使用了,就检查bit,如果已被发送,就清除并写入。如果全部写完了,就返回错误。
接收也一样,有一个ring,每个指向一个buf,网卡会通过DMA写入buf,然后发出中断要求处理,我们就读取buf,然后将ring中的描述符初始化并重新分配buf就可以了。
e1000
xv6 网络调用链
首先是发送调用链。
Linux 万物皆文件,xv6 亦是如此。上层若想发送网络包,那就要通过系统调用 sys_write() 来写“文件”。接着,调用 filewrite() ,其在最后会判断写入的文件类型是不是套接字(FD_SOCK)。如果是,那么就调用 sockwrite() ,至此运输层开始。sockwrite() 会给报文分配一个空间用于写数据,接着调用 net_tx_udp() 来进行 UDP 封装,封装完成后进一步调用 net_tx_ip() 进行 IP 封装,随后进一步调用 net_tx_eth() 进行链路层封装。最后,通过调用 e1000_transmit() 来使用 E1000 发送链路帧,这部分需要我们自己实现,后面就是硬件的活了。上述函数都是嵌套调用的,故 xv6 发包的流程如下:
sys_write() -> filewrite() -> sockwrite() -> net_tx_udp() -> net_tx_ip() -> net_tx_eth() -> e1000_transmit()
然后是接收调用链。
要明白 xv6 是如何知道 E1000 收到链路帧了,是通过中断。每当 E1000 收到一个链路帧时,就会触发对应的硬件中断。在 usertrap(),会通过 devintr() 来进入硬件中断处理入口。devintr() 会先判断硬件中断的类型,如果是 E1000_IRQ,就说明是 E1000 产生的中断,接着进入 e1000_intr() 处理该中断。随后,调用 e1000_recv() 来处理介绍到的链路帧,这部分需要我们自己实现,个人认为接收比发送要难。 e1000_recv() 中会调用 net_rx() 对链路帧进行解封装,并将其递交给网络层。之后,根据包类型调用 net_rx_ip() 或是 net_rx_arp() 来进一步向上递交,前者是 IP 报文后者是 ARP 报文。对于 IP 报文,进一步调用 net_rx_udp() 将其解封装为 UDP 报文。随后,调用 sockrecvudp(),其会进一步调用 mbufq_pushtail() 来将报文放入一个接收队列。此后,上层就可以通过 sockread() 来从队列中读出该报文了。而对于 ARP 报文,其本身不再有运输层报文,因此不会向上递交,而是会调用 net_tx_arp() 来进行一个 ARP 回复。故 xv6 收包的流程如下:
e1000_intr() -> e1000_recv() -> net_rx() -> net_rx_ip() -> net_rx_udp() -> sockrecvudp() -> mbufq_pushtail()
E1000 收发模型
E1000 使用 DMA 模型(Direct Memory Access),也就是内存直接访问。在学计网的时候我们知道,任何处理网络包的终端都会有一个缓冲区,这是该硬件自带的,E1000 也不例外。但是,E1000 自带的空间毕竟太小了,因此 E1000 将会直接使用主机内容来作缓冲区,也就是内存直接访问。这也是为什么,在实现代码时会发现,所有的包空间都是最终都是通过 kalloc 来分配空间的。
锁
指令级:TAS,CAS
组成自旋锁,睡眠锁等
如何实现多级inode?
xv6 inode contains 12 “direct” block numbers and one “singly-indirect” block number
所以它的大小很小,这里要实现的就是两级的block
删除这个单级的block,然后增加一个二级的block
这个block号指向一个block,这个block中存的全是block号,每个block号又指向一个block,这个block中全是block num,然后这些block保存数据
文件系统?
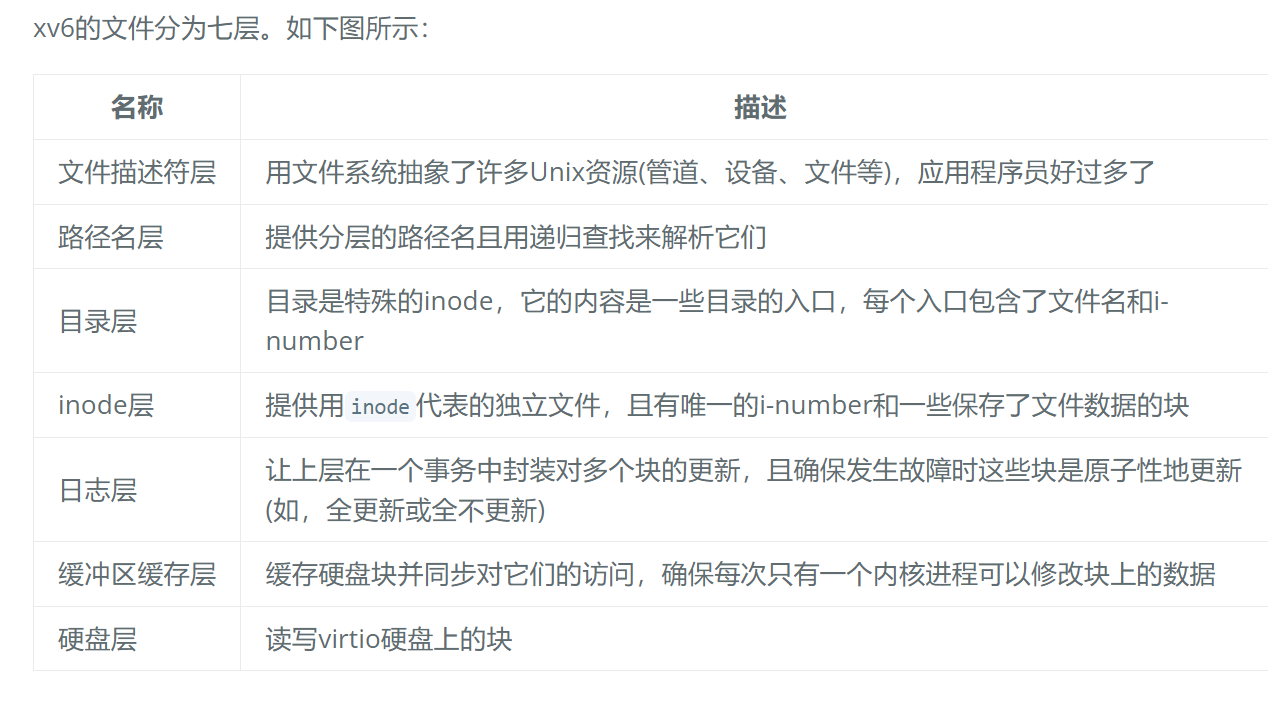
**磁盘层:**块1是超级块(superblock),包含了文件系统的元数据(文件系统里块的数量,数据块的数量,inode的数量,日志区里块的数量)。从2号块开始是日志区。日志区之后是inode区,每个块有多个inode。之后是位图区,用于追踪哪个块被使用了。剩下的是数据区,数据区里的块要么在位图区被标记为空闲,要么保存文件或目录的内容。超级块由一个叫mkfs的单独的程序填充,这个程序构建了一个初始的文件系统。
**缓冲区层:**缓冲区缓存有一个确定数量的缓冲区来保存磁盘块,这意味着如果文件系统请求了不在缓存中的磁盘块,缓冲区缓存必须回收一个已经保存了其它块的缓冲区。缓冲区缓存回收的是最近最少使用的缓冲区。
**日志层:**它把一个描述放在磁盘上,这个描述是它在一个log里所期望的所有磁盘写操作。一旦系统调用日志记录了所有的写操作,它往磁盘上写入一个特殊的commit记录用来表示那个日志包含了一个完整的操作。那时系统调用才会把复制写入到磁盘文件系统里的数据结构。当那些写操作都完成后,系统调用删除磁盘上的日志。如果日志被标记为包含一个完整的操作,则恢复代码把写操作复制到磁盘文件系统。如果日志不是标记为包含完整的操作,恢复代码忽略这个日志。恢复代码最后删除日志完成所有的操作。
日志驻留在固定的位置,这是在超级块里指定的。它是由一个头块(header block)和随后跟着的一些要更新的块的复制(updated block copies)组成的,要更新的块的复制也叫日志块(logged blocks)。头块由扇区编号的数组和日志块的计数组成,其中每个扇区对应着一个日志块。头块中的计数如果是0则表示日志中没有事务,如果非0则表示日志中包含一个完整的已提交事务。xv6在事务提交的时候(不是之前)写头块,在把日志块复制到文件系统之后将计数置0。因此事务进行到一半的崩溃将导致头块里计数为0;而提交之后的崩溃将导致计数非0。
提供给上层开始op,写入log,end_op的接口。end_op会将缓冲区中的buffer写入磁盘log区,并在最后写入log区的头块,代表提交。然后从日志中读取数据并写入对应位置,写入完毕后更改头块的信息,并删除log。
**块分配器:**块分配器管理着一个磁盘上的空闲位图,每个位对应着一个块。
**inode层:**内核把活动inode的集合保存在内存中,即struct inode。只有在一个C指针指向一个inode的时候内核才会把那个inode保存到内存里。ref字段记录了C指针引用内存里inode的次数,当那个计数降为0的时候内核就会从内存中丢弃这个inode。iget和iput函数请求和释放到一个inode的指针,这会修改这个引用计数。到inode的指针可能来自于文件描述符、当前的工作目录,和事件内核代码(如exec)。
**目录层:**目录的内部实现非常类似于文件。它的inode的类型是T_DIR,它的数据是一些目录条目。每个条目都是一个struct dirent,包含了一个名字和一个inode号。名字最多可以有DIRSIZ(14)个字符;如果低于14个字符,则以NUL(0)结尾。inode号为0的目录条目是空闲的目录条目。
**路径层:**namei和namex等
**文件层:**文件描述符,是对管道和inode的封装。。inode中需要包含引用计数,在为0时可以被释放(磁盘inode也需要,可能用于硬链接)
如何实现的符号链接?
符号链接也就是文件中存另一个文件的路径,还需要给它的文件类型标注为符号链接
O_UNFOLLOW 要在用户库中设置,还要在syscall中设置
open函数在检查了文件类型之后,如果是符号链接,会自动递归调用,我们要做的就是检查flag阻止递归调用。
啥是硬链接?
多个 dirent 指向同一个 inode
所以不能跨文件系统。